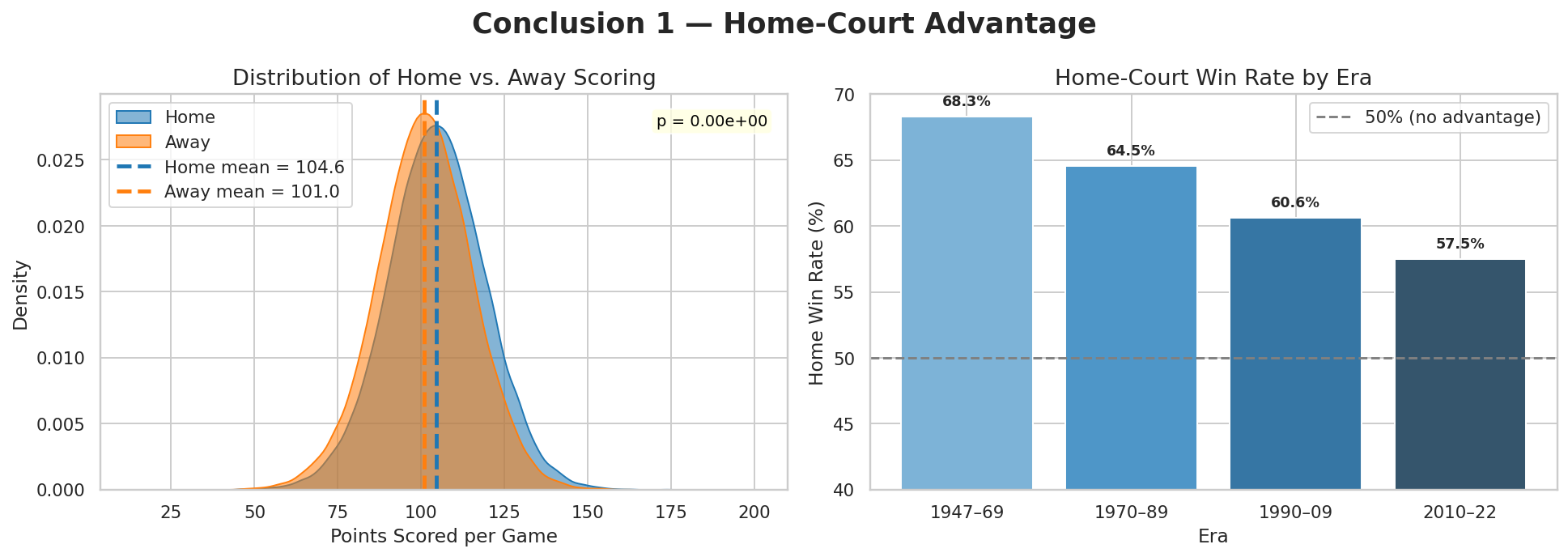
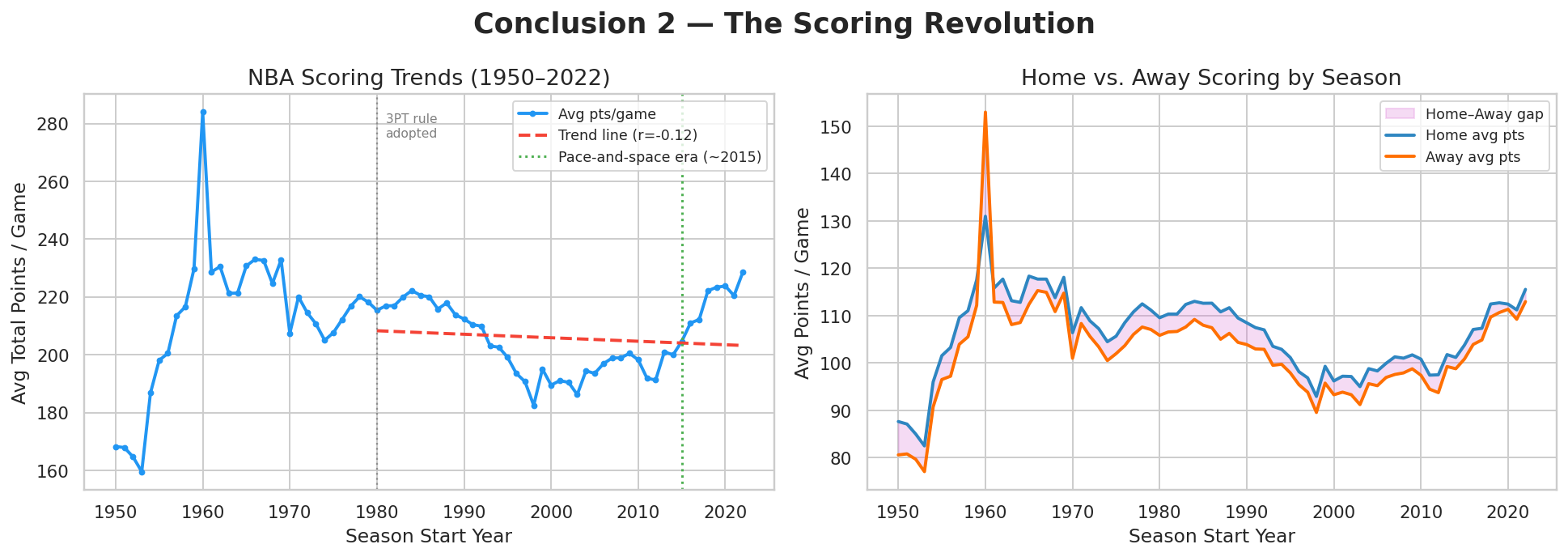
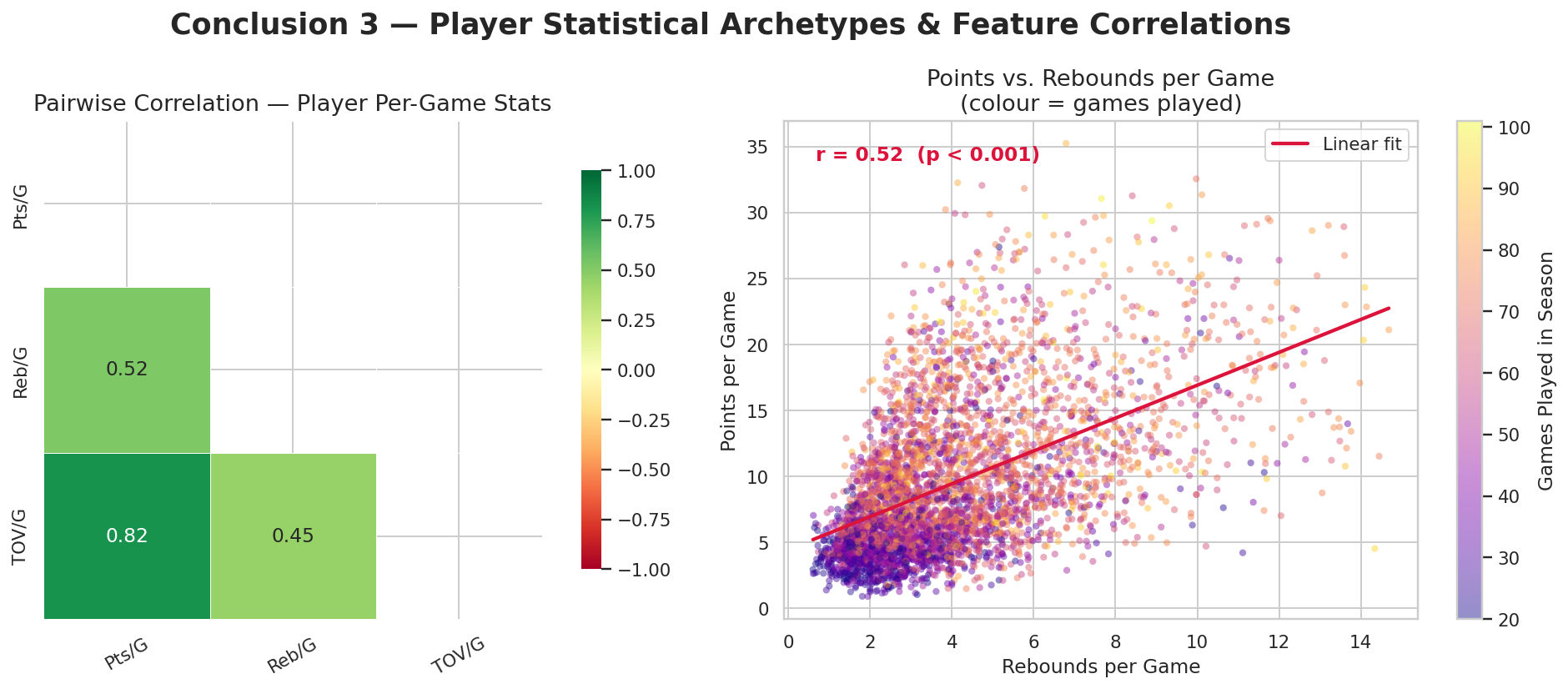
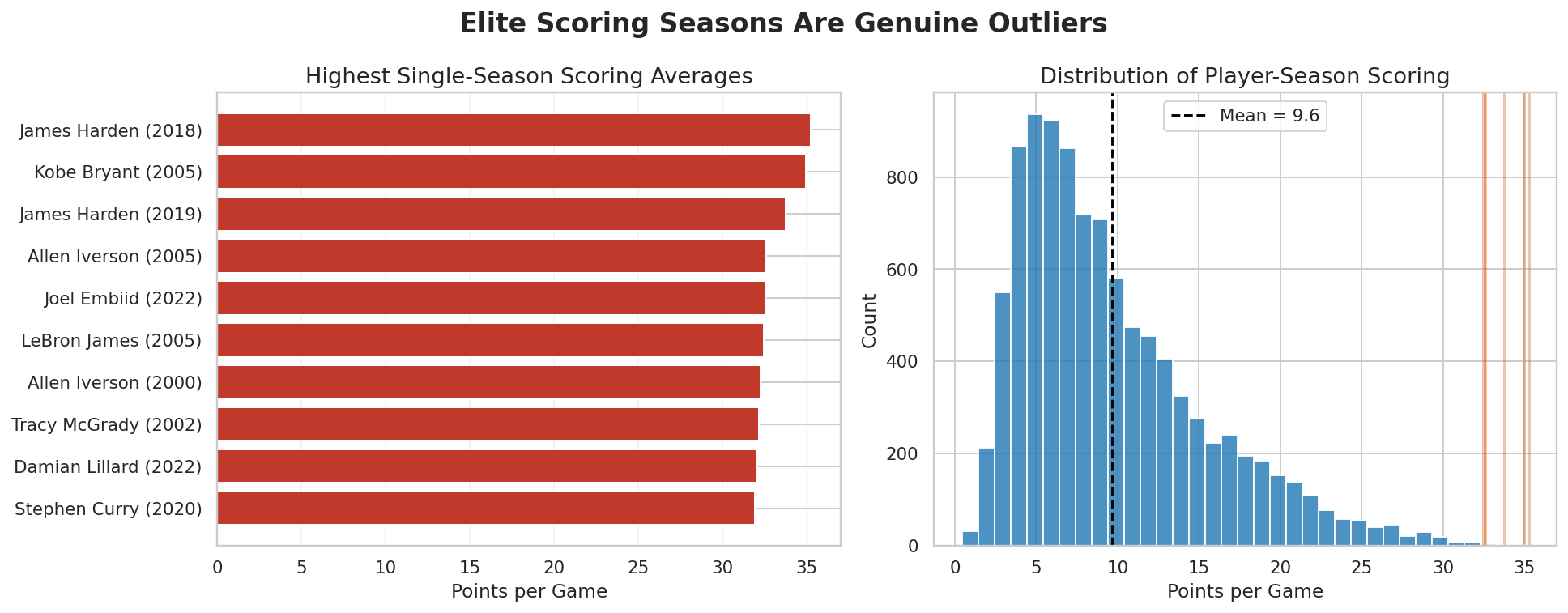
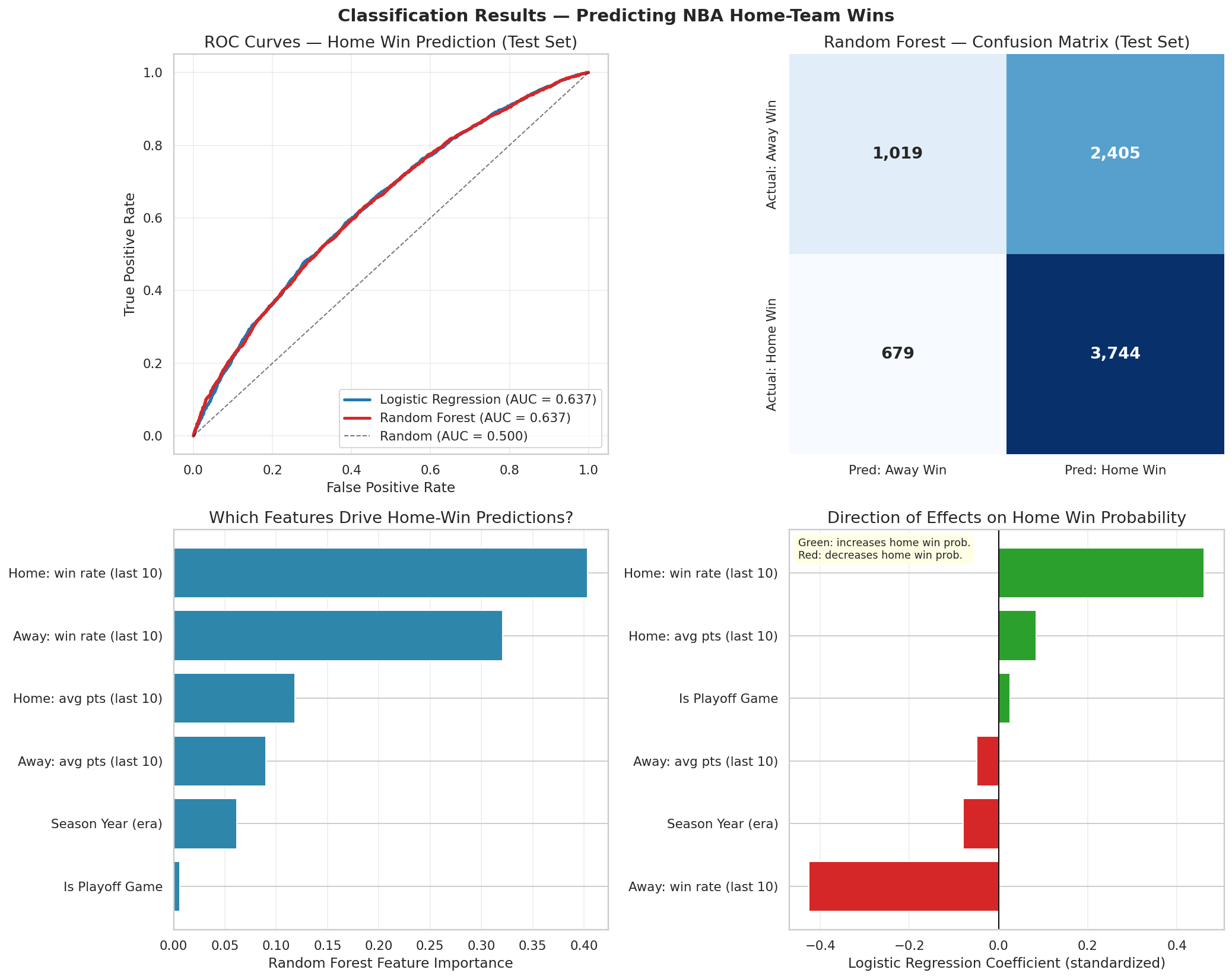
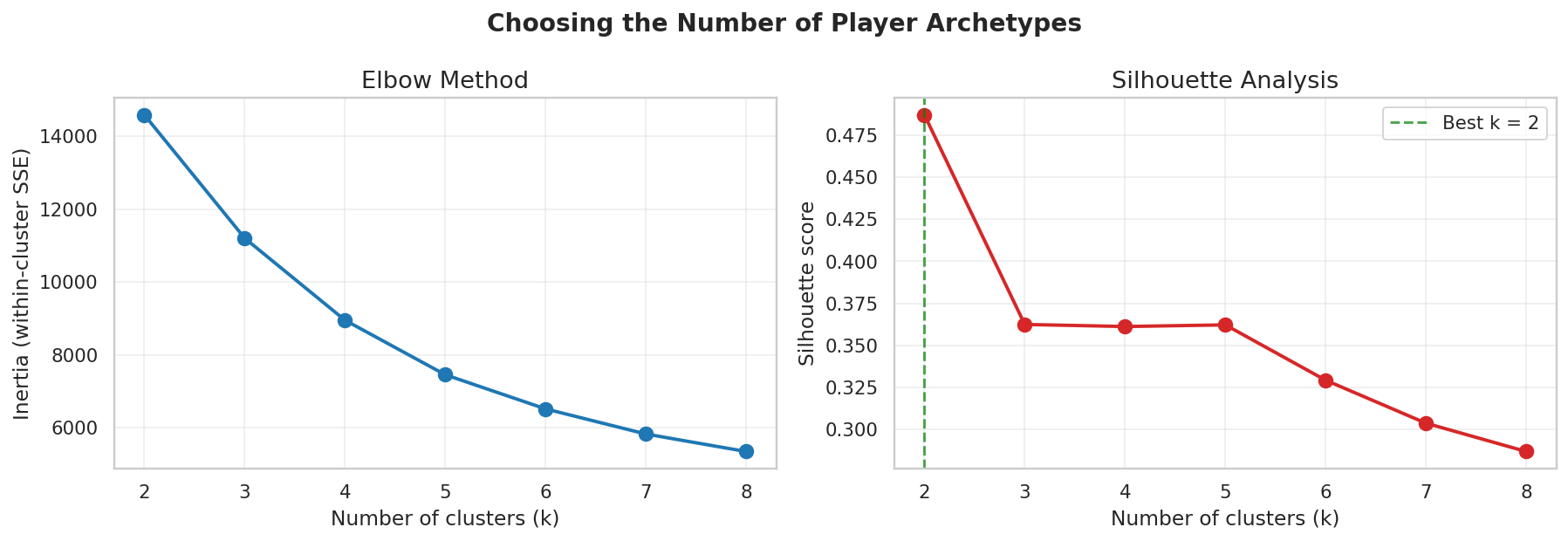
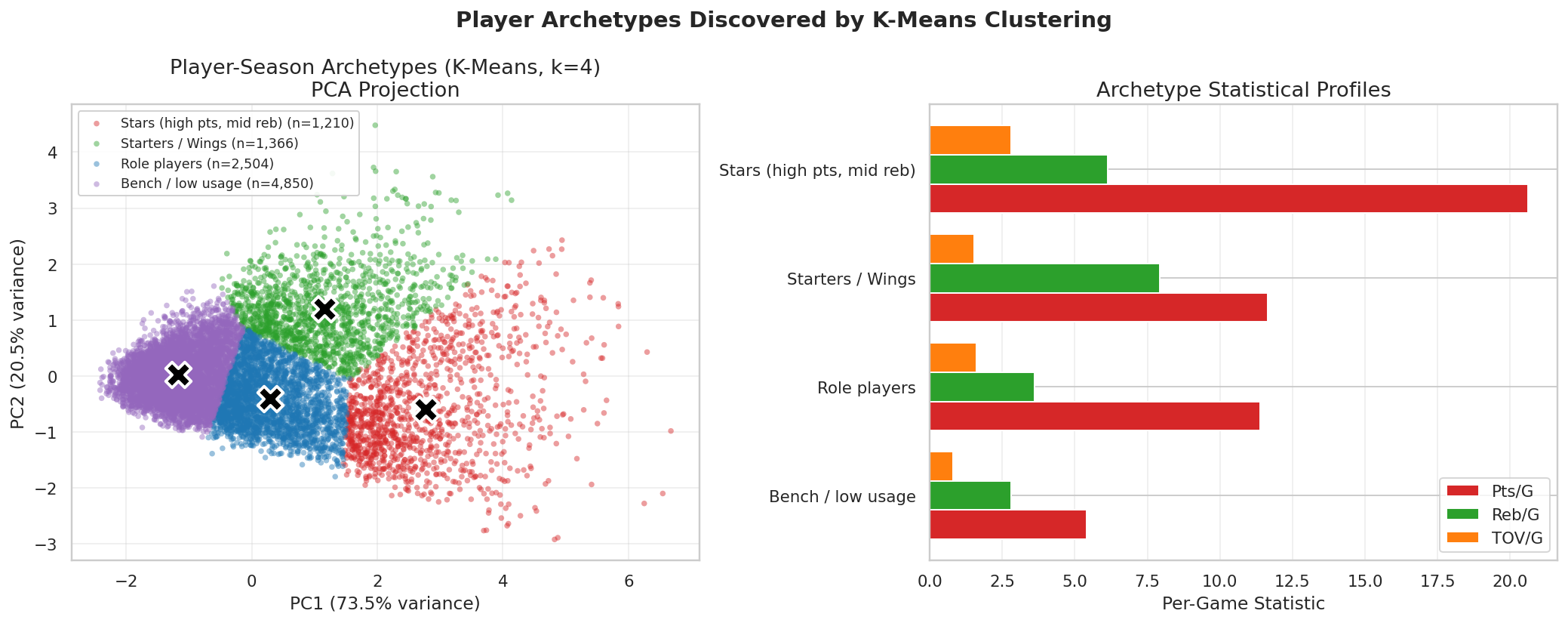
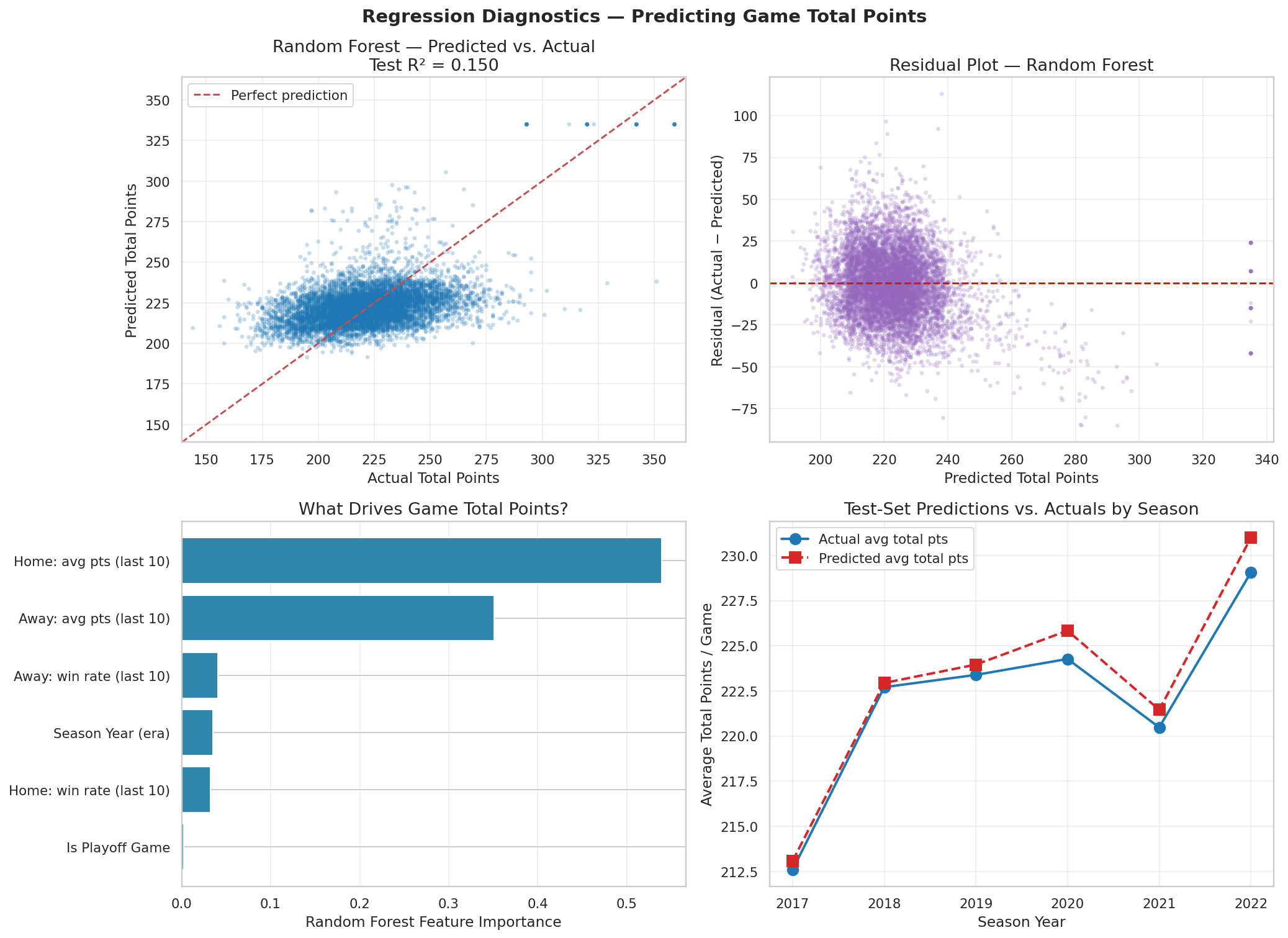
Build player-game and player-season tables
Once events are classified, we aggregate them to player-game rows and then to
player-season averages. This gives us the unit of analysis for our player-archetype
work.
box = scoring.merge(rebounds, on=['game_id','player1_id','player1_name'], how='outer')
box = box.merge(turnovers, on=['game_id','player1_id','player1_name'], how='outer')
box.rename(columns={'player1_name': 'player_name', 'player1_id': 'player_id'}, inplace=True)
box[['pts','reb','tov']] = box[['pts','reb','tov']].fillna(0)
player_season = (
box_with_season
.groupby(['player_name', 'player_id', 'season_year'])
.agg(
games_played=('pts', 'count'),
pts_pg=('pts', 'mean'),
reb_pg=('reb', 'mean'),
tov_pg=('tov', 'mean'),
)
.reset_index()
)
player_season = player_season[player_season['games_played'] >= 20].copy()
The minimum-games threshold is important. Without it, short and noisy seasons would
dominate the tails of the distribution and make the player plots less trustworthy.